Equivalence Partitions and Boundaries are key concepts in software testing that contribute to more efficient and thorough
evaluation of a system's functionality.
Equivalence Partitions involve dividing the input data of a software component into subsets that are expected
to exhibit similar behavior. By identifying representative values within each partition, developers can minimize
the number of test cases while still ensuring comprehensive coverage.
Boundaries, on the other hand, refer to the edges of these partitions, where input values often transition
between distinct behaviors.
As many software defects arise from incorrect handling of boundary conditions,
thoroughly testing these boundaries is crucial for identifying potential issues and enhancing the
overall reliability of the system.
Together, Equivalence Partitions and Boundaries help developers create effective test cases,
optimize testing efforts, and improve the quality of the software delivered.
This is best illustrated with an example.
Given the following function:
public string Print(int input)
{
if (input <= 0) return "TDD";
if (input > 0 && input <= 99) return "is";
return "awesome"; //Anything 100 or above
}
There are 3 equivalence partitions:
- "TDD", which groups all input values that are less than or equal to 0
- "is", which groups all input values from 1 to 99
- "awesome", which groups input values greater than or equal to 100
There are 2 boundaries:
- "TDD" - "is"
- "is" - "awesome"
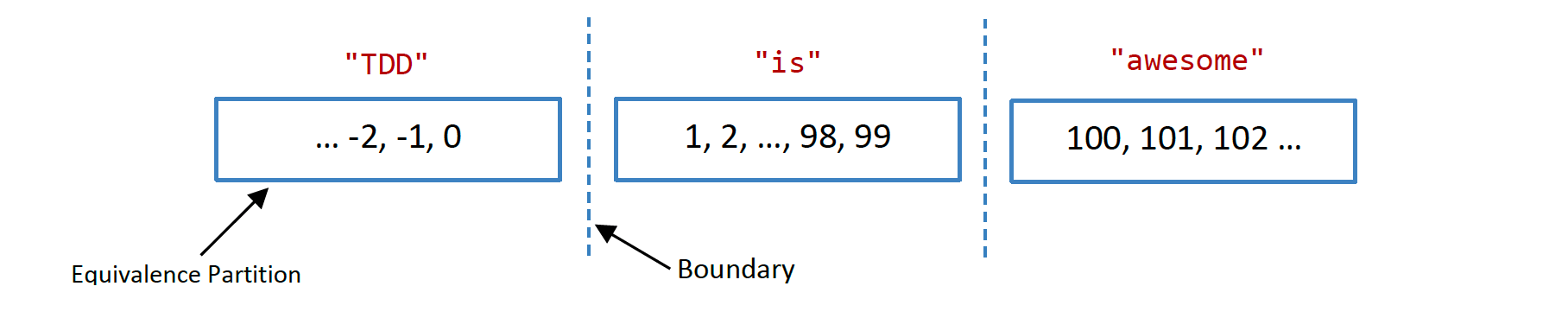
Figure 1: boundaries and equivalence partitions for the Print() function
Identifying boundaries and equivalence partitions allow for a more systematic and comprehensive approach to testing, automated or manual. The input values before, after and on each boundary, should be used to test with. Sometimes there is no actual value on the boundaries, in these cases, the values before and after each boundary are used.
Looking at the above example you would test using 0 and 1 as input values from the "TDD" - "is" boundary and 99 and 100 from the "is" - "awesome" boundary. Selecting your tests this way increase the chances of finding the infamous and far too common off by one error that happens around boundaries. It also means your tests have a higher chance of covering all the different behaviors that exist in the code being tested.
In the above Print() function the values in the equivalence partitions are linear/sequential. This isn't a rule. Value in a equivalence partition can also be non-linear/non-sequential.
To illustrate this let's use another example.
Given the following function from the FizzBuzz kata:
public string GetFizzBuzz(int input)
{
if (input % 15 == 0) return "FizzBuzz";
if (input % 3 == 0) return "Fizz";
if (input % 5 == 0) return "Buzz";
return input.ToString();
}
There are 4 equivalence partitions:
- "FizzBuzz", which groups all input values that divisible by 3 and 5 (15).
- "Fizz", which groups all input values that divisible by 3.
- "Buzz", which groups all input values that divisible by 5.
- Other, which groups all input values that aren't divisible by 3, 5 or 15.
There are 3 boundaries:
- Other = "Fizz"
- "Fizz" - "Buzz"
- "Buzz" - "FizzBuzz"

Figure 2: FizzBuzz equivalence partitions and boundaries
When identifying equivalence partitions and boundaries look for where behavior changes. A behavior change indicates a boundary. Once the boundaries are identified, group all input values causing a behavior into an equivalence partition.